![]()
Dariusz J. Kogut (for the TORCH section)
In this paper the CERN central servers' configuration will be discussed. The choice of commercial and public domain software for the server, search engine, Web discussion forums and log statistics will be presented. The guidelines and recommendations on Web authoring and site management will be listed as well as the criteria that led us to these conclusions.
Managing a very large Intranet and, by the way, the oldest one, may seem at first glance to be a straight forward technical issue but it is more than that. It touches upon very interesting human and social aspects like:
Our Intranet is far from being the most attractive and conscise, however, the following statements are all true and explain or justify the situation:
Experience has shown that trying to over-centralize and control the presentation, location, platform or number of the CERN web page/sites/servers is a utopia, anyway contrary to the design and philosophy of the Web, the "universe of network-accessible information" (Tim Berners-Lee).
What we found realistic and valuable was to offer solid and open solutions that would prove themselves performant and simple to adopt or comply. These solutions were made available on the central web server www.cern.ch for those who have no resources to set-up a service of their own. They were also documented as tools, courses and guidelines for those who want to stay independent and run their own service, with the possibility to get advice.
This work covered the period of 1997-98 and is summarized here. As people and strategies change there is no commitment that the policy (or URLs!) of this paper will remain valid in the distant future.
CERN was, of course, using the home-made CERN httpd from the web's birth till June 1998 when the central server www.cern.ch converted to Apache (some other servers on-site had done this earlier). It has been amazing to notice the performance degradation observed during the last year of use of the CERN httpd and it was very hard for us to identify the reason for that blockage. We upgraded the hardware, doubled the CPUs, added memory, increased the afs cache, monitored the impact of cgis running on the host, to witness in practice that the CERN httpd simply doesn't scale enough over a certain number of hits (~100K requests/day or on average 4 requests/sec). This was suggested by Jes Sorensen/CERN and proved to be true after we installed Apache and concluded to the following values for the httpd.conf tuning parameters:
Apache proved to be a very powerful Web server.What we appreciated the most in Apache was the use of Virtual Web Servers, Server Side Includes and the handling of page protections.
The Virtual Web Servers allowed us to host those web sites that didn't have resources to maintain their own system any more but wanted to keep their identity (URLs) unchanged.
The Server Side Includes helped us create and maintain a uniform look on our service pages and every time site-wide changes were needed the update had to be done only in one place.
Most information owners want to know who visits their pages and ask for the possibility to access the Apache logs and extract the information that concerns them. We chose the analog package to do this by making available to the user a list of fields and tailorable parameters they can select and make statistics reports for the period, the criteria and the format that suit them.
Another preoccupation every system manager has when running a web server on his/her system is the potential security risks of CGI scripts. To ensure some safety we decided to keep all scripts in one place. Their authors aren't allowed to move them there by themselves but need to submit them to a programmer of the web support team for checking of potential security holes. Some documentation was made available recently on typical errors in Perl with shell commands and file I/O.
(*)"L'enfer c'est les autres" J-P. Sartre
The challenges in this area depend:
The above do not concern page/site style, fonts and content but only version consistency, document portability and write permissions.
We started by making an inventory of the tools available in the market for page editing, site management and image processing. It was immediately obvious that it is a never-ending task to keep it up-to-date, evaluate all of the packages or support more than a handful of them.
Therefore, we evaluated a subset of these products against a list of criteria and concluded that:
The products we actually examined more carefully were:
Their page editing facilities are very similar i.e. link insertion, list,template and table creation are quite easy etc.
The worries start when proprietory add-ons reduce the portability possibilities of the end-product.We needed to come up with a recommendation in a finite amount of time and suggested the Macromedia Dreamweaver for medium-sized sites not for its perfection (there are bugs!) but for its open,straight-forward, W3C standards' compliant features. Some of them, not exhaustive nor exclusive are:
From the page usability point of view one of the most serious problems we have due to the large number of authors (over 1,000) and the lack of coordination is the quality of the page content. Pages are written and forgotten, authors leave the organization, users don't know whom to contact to find out what is still valid. Some of our collaborators in the 20 member States of the laboratory or the rest of the world have modest network connectivity and can't use sites heavily loaded with images and animations. For these reasons we issued guidelines to authors explaining that on every page there should be:
Some management structures were also put in place per functional unit in the laboratory to assign webmasters in each administrative group so that some homogeneity and information update can be achieved.
An unsolvable problem is the choice of URL names. Every time the administrative structure was reflected in the file path or the URL we had a problem to keep it meaningful for more than a year. To this, we hardly have anything better to offer that tumb-stones and Redirects to the pages' new location. In the process some links break. For such checkings and web-based communication within working projects we have selected or developed a few tools explained below.
In 1997 we decided to buy a proper search engine because:
In order to select a search engine we made a list of requirements like:
We found all of the above requirements quite well implemented in the Ultraseek server by Infoseek, with its recent enhancement the Content Classification Engine.
Indexing works by following links. Web documents not linked from anywhere will not be indexed but can be added manually by the author if they are allowed by the configuration filters. This is meant to protect against unauthorised inclusion of foreign pages in the CERN index. As our (>=300,000) pages in index are too many and their scope too vast, we developed a sub-search facility in Perl for authors who only want to narrow down searches in their part of the directory tree. This was very much used and appreciated.
Happy with the basic features of our search engine as administrators we found that our users had problems to manipulate well the commands that narrow down searches to the best-matching answers. For this reason we developed an additional layer on-top of the standard user interface that allows typing queries in plain english text. This application is explained below.

The diagram below describes TORCH main components.
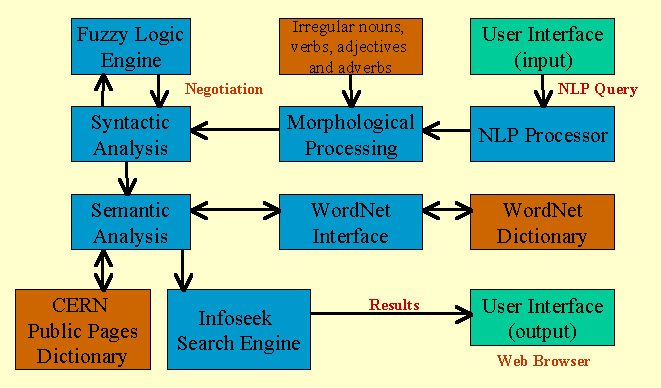
TORCH has been created in Python language (http://www.python.org)
and implemented as a part of Infoseek Search Engine. TORCH performs a syntactic
(including fuzzy logic negotiation) and semantic analysis of a given query.
It retrieves synonyms, antonyms, hypernyms and hyponyms from WordNet Dictionary
to make the searching more efficient. Afterwards it tries to find a definition
of each keyword in CERN Public Pages Dictionary that extends TORCH knowledge
on the advanced particle physics. If the definition is found it will be displayed
on the user interface web page. As far as CERN Public Pages Dictionary is concerned
the definitions are stored as a piece of HTML code so all the advantages of
hypertext language could be used. TORCH builds its own Infoseek Search Engine
query during the semantic analysis process. In general, the query starts with
proper nouns followed by a strategic keyword. Next phrases, nouns and adjectives
appear. CERN coordinate terms are stuck together and placed at the end of the
query. Due to its open architecture, TORCH may be easily maintained and developed.
Ā
History teaches us that who was once first in a field will not stay at the top for ever. However, a long tradition gives awareness and the ability to critically think whether something is a gift or a trap. A service operation like web support is most succesful when based on open products, minumum centralization, clear recommendations and well-founded guidelines that reflect the technology solutions of the present.
To Tim Berners-Lee for his creativity, modesty and integrity. To Robert Cailliau for reminding me often that things should be made "as simple as possible, but not simpler" and to Darek Kogut for his discrete devotion to the TORCH development.